
Since the early days of Kubernetes, autoscaling has held tremendous promise for organizations that want to reduce resource waste while ensuring service availability and performance. Out of the box, Kubernetes includes two approaches for application autoscaling: the horizontal pod autoscaler (HPA) and the vertical pod autoscaler (VPA).
In theory, this is great. Resources can be dynamically adjusted in response to changing usage either by adding or removing replicas, or by changing resource allocation at the container level. However, according to Datadog, only 40% of organizations that use Kubernetes in production are running the HPA, and less than 1% are running the VPA. And those that are using the HPA are often wasting resources at an unsustainable rate.
Why are so few organizations leveraging these technologies, and why is there still so much waste?
First, HPA and VPA can’t be used together by default. Because the HPA and VPA both scale based on CPU utilization by default, thrashing will result if both are used together on the same application. While it is possible to configure both the HPA and VPA to scale based on a custom metric, the time, effort and expertise required to do so makes this a nonstarter for most teams.
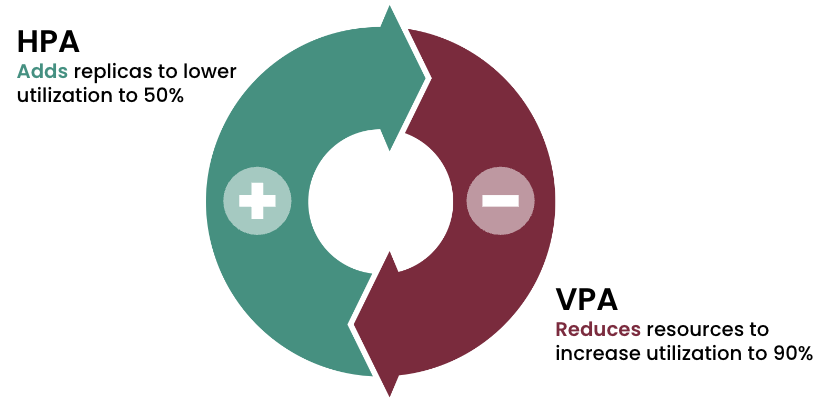
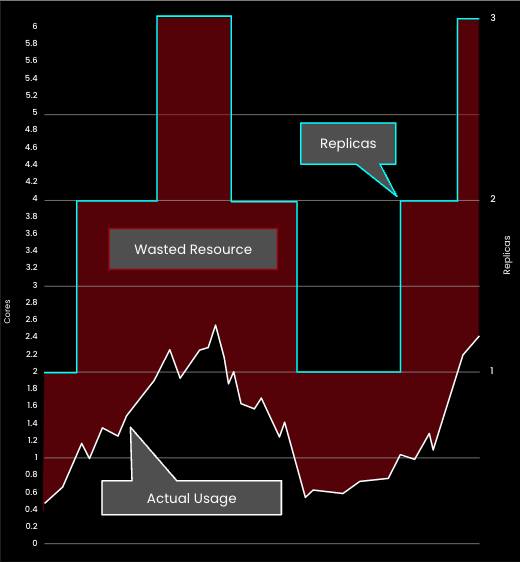
Second, the HPA doesn’t scale “intelligently.” By that we mean that the HPA requires the user to determine not only replica size, but also what target utilization to use, i.e. the threshold where replicas are added or removed. However, users have no way of knowing how to set these parameters to minimize waste. What’s optimal for one scenario may result in significant risk for another. So, most teams will tend toward over-provisioning and setting target utilization conservatively to reduce risk, resulting in significant waste.
The new version of StormForge Optimize Live gives teams the ability to combine the benefits of horizontal and vertical pod autoscaling to maximize the savings that can be realized from autoscaling. How does it work?
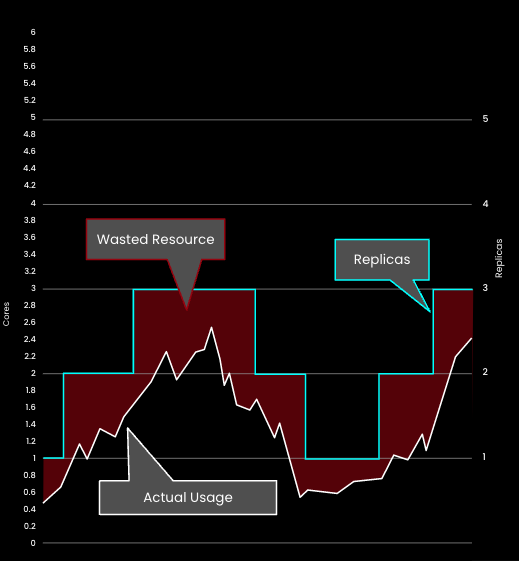
Not only does StormForge Optimize Live enable vertical and horizontal autoscaling to work together, it also makes the HPA smarter and more efficient. StormForge machine learning analyzes historical usage to find the sweet spot for setting the HPA target utilization that minimizes waste without sacrificing application performance or availability.
And because things are constantly changing in production, StormForge keeps watching, analyzing, and updating recommendations at a frequency that you can customize. The result is bi-dimensional autoscaling that is continuously operating to ensure peak efficiency, performance and reliability.
Getting started with bi-dimensional autoscaling is easy with StormForge Optimize Live. Just set up your application and enable recommendations. If you are running an HPA, StormForge automatically detects it and provides recommendations for HPA target utilization along with the pod-level CPU and memory recommendations it normally provides for vertical scaling. Recommendations can be configured for automatic implementation or manual approval.
That’s all there is to it! Now just sit back and leave the work to StormForge. Our machine learning will start recommending configuration updates within hours to improve efficiency.
Learn more about Optimize Live's bi-dimensional autoscaling with these resources:
We use cookies to provide you with a better website experience and to analyze the site traffic. Please read our "privacy policy" for more information.


