
A wise man once said, “We used the cloud for our digital transformation. Why not use it for sustainability transformation as well?” (Adrian Cockcroft, VP Amazon Sustainability Architecture 2021).
All major cloud providers have undertaken significant efforts to improve sustainability of the cloud but the ultimate responsibility for sustainable use in the cloud is on us as a tech community. Theoretically, Kubernetes allows for highly precise resource utilization and minimal cloud waste. But in reality there are many good reasons why we have not yet reached this goal.
In this article, we will look at the current impact of the cloud on sustainability, reasons that might hold us back to become more resource efficient in the cloud and provide recommendations on making Kubernetes a powerful tool for sustainability.
The container orchestration system has dominated the space for years already but the latest report on the state of Kubernetes shows the adoption within large organizations has reached a point that it can’t be ignored anymore. More than 45% of large organizations across the globe run 25 or more Kubernetes clusters – this is an increase of large-scale Kubernetes deployments of nearly 100% compared to the report 2 years ago. Main factors driving this growth are the perceived increase in flexibility, improved cloud utilization as well as the improvement in developer efficiency.
The adoption of Kubernetes and the drivers for its growth are a great foundation to think about next steps to reduce the environmental impact of our digital lifestyle and maybe free up some cloud budget along the way for other projects within your organization.
Some people might expect to hear a lot about the carbon footprint being the problem for computing and its continuous growth. You can find plenty of striking yet questionable claims circulating the net about carbon emissions of things we do everyday, like watching Netflix for 30 minutes emitting as much carbon dioxide as driving your car for four miles. But a closer look at such claims reveals that these are originating from extrapolation-based models using bottom-up studies about electricity demand of data centers, often a decade old.
Over the past 10 years, a lot has happened in terms of datacenter efficiency. Much more efficient hyperscale data centers have emerged, new processors like AWS Graviton have been introduced and cooling technology has become much more efficient.
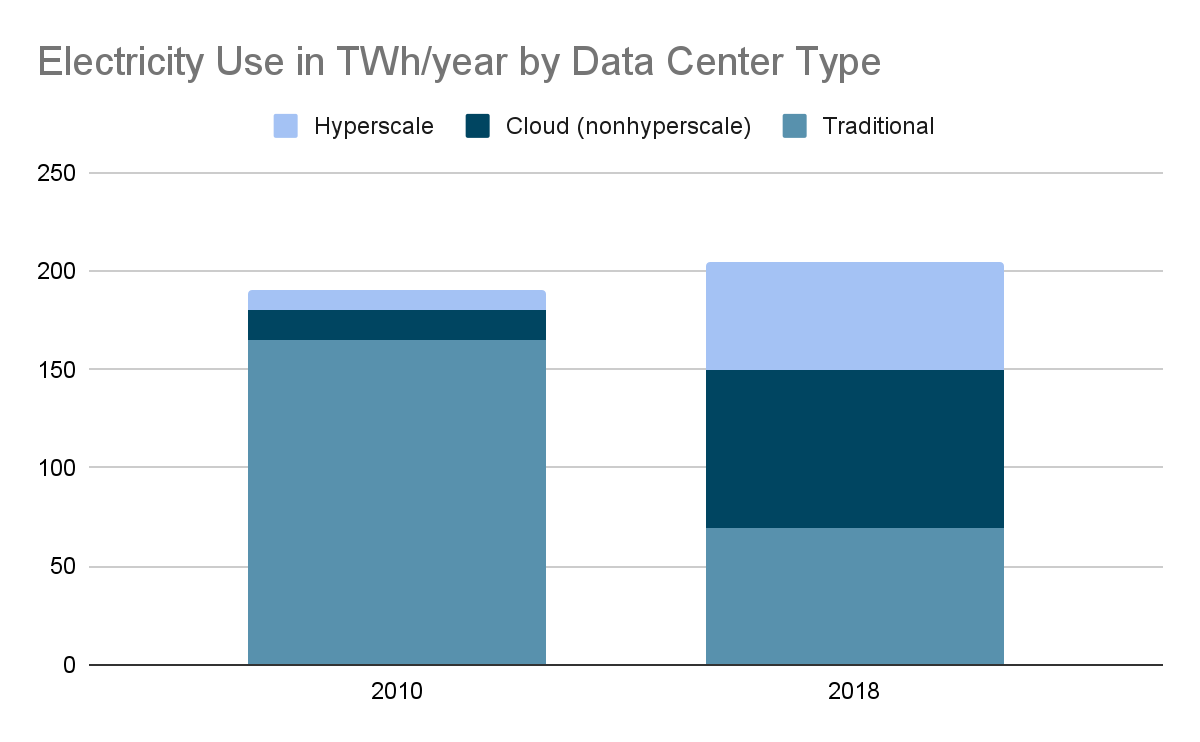
Furthermore, all major cloud providers like AWS, Google and Azure have significantly increased the percentage of their energy usage coming from renewable sources. So, if carbon emissions of the cloud are not necessarily the problem then what is?
There are new technologies emerging which require much more computing and therefore electricity. For instance, the increasing speed of digitalization as well as the rise of machine learning and AI probably outpace the efficiency gains of data centers. Furthermore, our cloud applications do not live in a vacuum. Industrial IoT and the transition to electric mobility is already challenging grids, even in modern countries. Together with the lack of storage capacity for green electricity even in the United States and Europe (currently 0.0013% of consumption), it appears quite important to think about resource efficiency of our cloud-native infrastructure.
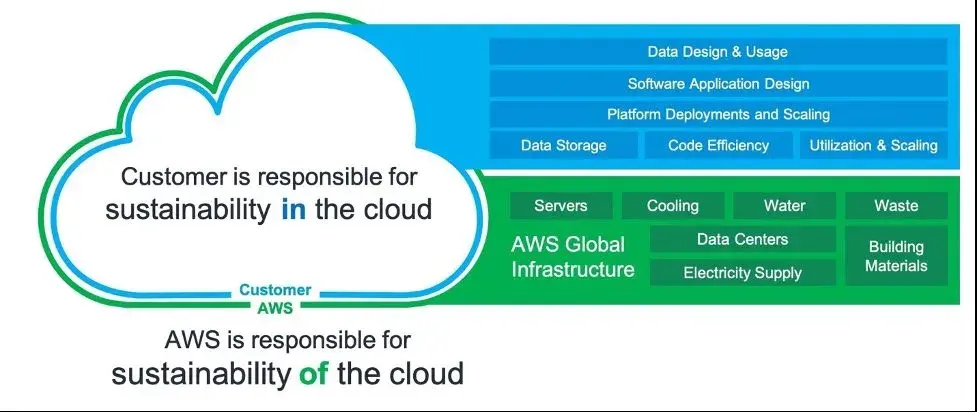
There is a shared responsibility when it comes to sustainability and cloud. As AWS pointed out in their recently published Sustainability pillar of their Well-Architected Framework, a cloud provider is responsible for the sustainability of the cloud but customers are responsible for sustainability in the cloud.
Kubernetes allows for a high degree of flexibility and accuracy when it comes to resource management. As you know, you can define resource requests and limits even at the container level with high precision. In conjunction with the ability to automate many processes, Kubernetes has the potential to provide an excellent basis for achieving peak efficiency.
Yet, we find a large amount of resource slack across cloud-native applications. In many cases up to 50% of provisioned (and paid for) resources are not utilized. There are many good reasons why this is, so let’s look at the most important ones to derive the features a better solution has to provide.
What are the biggest causes of cloud waste for your organization, in your opinion? Select all that apply.
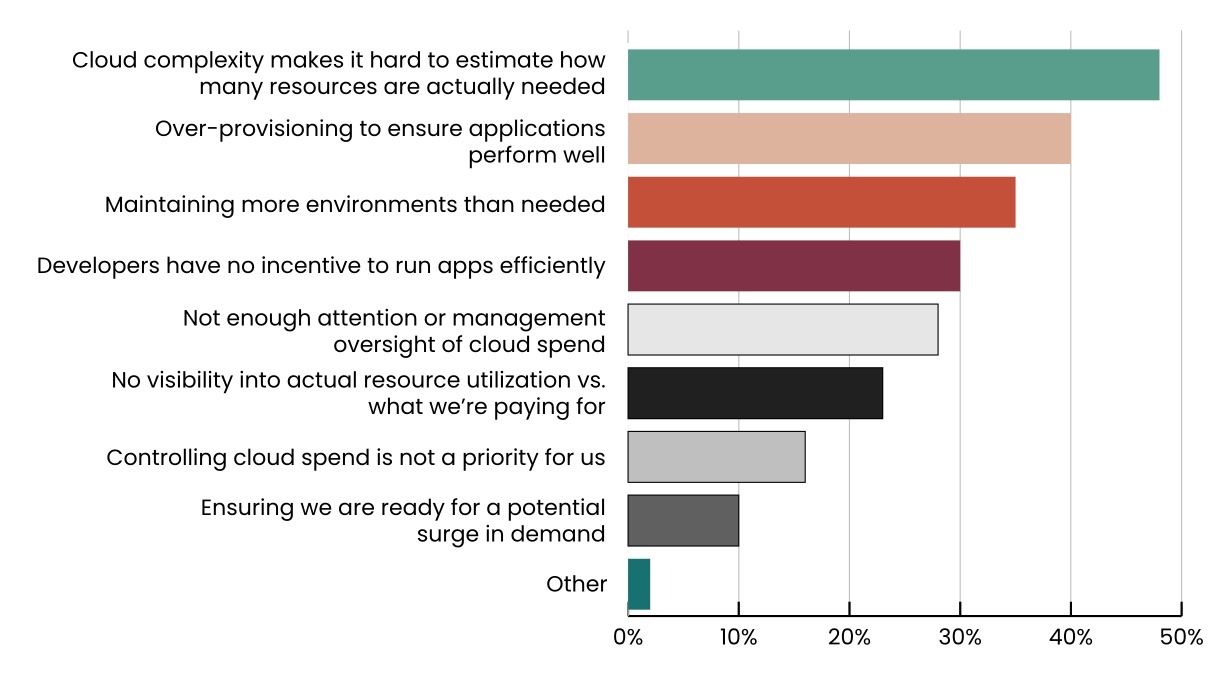
More than half of teams running Kubernetes report a lack of in-house skills/(wo)man power as their main challenge. Hence, it is only reasonable to invest your scarce talent into development, running and maintaining your Kubernetes deployments rather than optimizing resource efficiency.
Kubernetes is complex by itself and even mid-sized Kubernetes applications can easily have hundreds of containers. For peak efficiency, teams would have to load test each container, observe their behavior under certain load scenarios and derive the best configuration to be then manifested into complex YAML files and patched constantly.
Another big challenge is the broadly adopted concept of continuous integration and deployment. Production systems are changing constantly, making it extremely difficult to have a consistent state to be tested and a large enough time window to do so. Let alone that it might not be feasible to load test a production system while actual users are using it.
So far we’ve seen that we, as an exploding cloud-native community, can have a big impact on improving the sustainability of our industry and support other technologies to evolve. But there are challenges, which we cannot ignore. For a better way to have a real impact, it needs to achieve broad adoption by providing clear advantages for the team delivering the application and the business.
As we have seen in the previous section, Kubernetes skills are in short supply. Hence, a solution for improving resource efficiency needs to be simple and low touch. Site Reliability Engineers, DevOps, Platform/Kubernetes Engineers are already stretched. New engineers want to contribute to the team quickly and a solution should support this.
The load for each container defines the resources it needs. A solution should put its ear constantly on the load and resource demand signals which get captured by our observability tools. While it might be nice to watch shiny graphs it is not trivial deriving patterns from these huge amounts of data, especially when you want to identify recurring load patterns over a broader time window. As resource configurations are time-critical, a solution also needs to provide improvements in real-time.
Huge amounts of highly structured data. A complex optimization problem. Real-time improvement. Sounds like a job for machine learning to turn observability data into actionable improvements.
A more sustainable path forward will only take hold when it provides enough advantages compared to the status quo for the team and the business.
A better solution should be simple to implement and cheap to allow for its adoption already for smaller projects. The results should be easy to communicate also to non-technical members of the organization to improve the chances of their buy-in and budget approval. Furthermore, optimizing resources needed for Kubernetes should also have positive side effects for other teams like reducing OOM errors and CPU throttling so that people on-call do not have to wake up at night to save the day (again).
This post was originally published on VM Blog.
We use cookies to provide you with a better website experience and to analyze the site traffic. Please read our "privacy policy" for more information.


