Blog
Using Machine Learning to Improve Rightsizing Recommendations for Noisy and Seasonal Workloads
By Thibaut Perol | Apr 25, 2024
Blog
By Thibaut Perol | Apr 25, 2024
StormForge improves cost savings and reliability of Kubernetes applications by rightsizing all workloads, providing recommended values for the resource requests and limits. While this can be done manually for a few workloads, it does not work at scale. Most recommenders (VPA included) use simple statistics based on historical data to provide recommended requests and limits values, but this approach has limitations. Machine learning is the perfect fit for this problem, as it can draw correlations between containers, recognize patterns, and provide accurate forecasting capabilities.
By leveraging the power of machine learning, StormForge Optimize Live can analyze vast amounts of historical usage data, identify complex relationships and dependencies between containers, and generate reliable recommendations that adapt to changing workload patterns. This enables StormForge to deliver a far superior solution compared to traditional statistical methods, resulting in improved cost savings and application performance for customers.
Here’s an example of a resource configuration for a pod that StormForge might recommend:
apiVersion: v1
kind: Pod metadata:
name: example-pod spec:
containers:
- name: example-container
image: example-image
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 200m
memory: 512MiPercentile-based approaches for vertical rightsizing rely on the historical usage distribution of a workload to set the resource requests and limits. The process involves collecting the usage data across all replicas of a workload and calculating a percentile value from the usage distribution. The choice of percentile depends on the desired trade-off between performance and cost.
For simplicity, let’s consider the guaranteed quality of service (QoS) class, where the request to limit ratio is 1. In this scenario, overage occurs when the usage exceeds the request (which is equal to the limit), triggering CPU throttling. For example, using the 95th percentile (p95) for CPU request is considered efficient because it sets a value that only creates overage and subsequent CPU throttling for 5% of the usage. This means that the workload can tolerate occasional CPU throttling in exchange for lower resource allocation and cost savings. In some cases, users may choose to use the maximum value of the historical usage to be extremely safe, prioritizing performance over cost but potentially leading to slack (underutilized resources).
The approach for setting memory requests and limits often differs from CPU. Generally, users are comfortable with using a percentile of the CPU usage distribution because they can tolerate occasional CPU throttling. However, for memory usage, they often prefer using the maximum historical value to avoid out of memory (OOM) errors. When the request to limit ratio is 1, an OOM error occurs when the memory usage exceeds the request value.
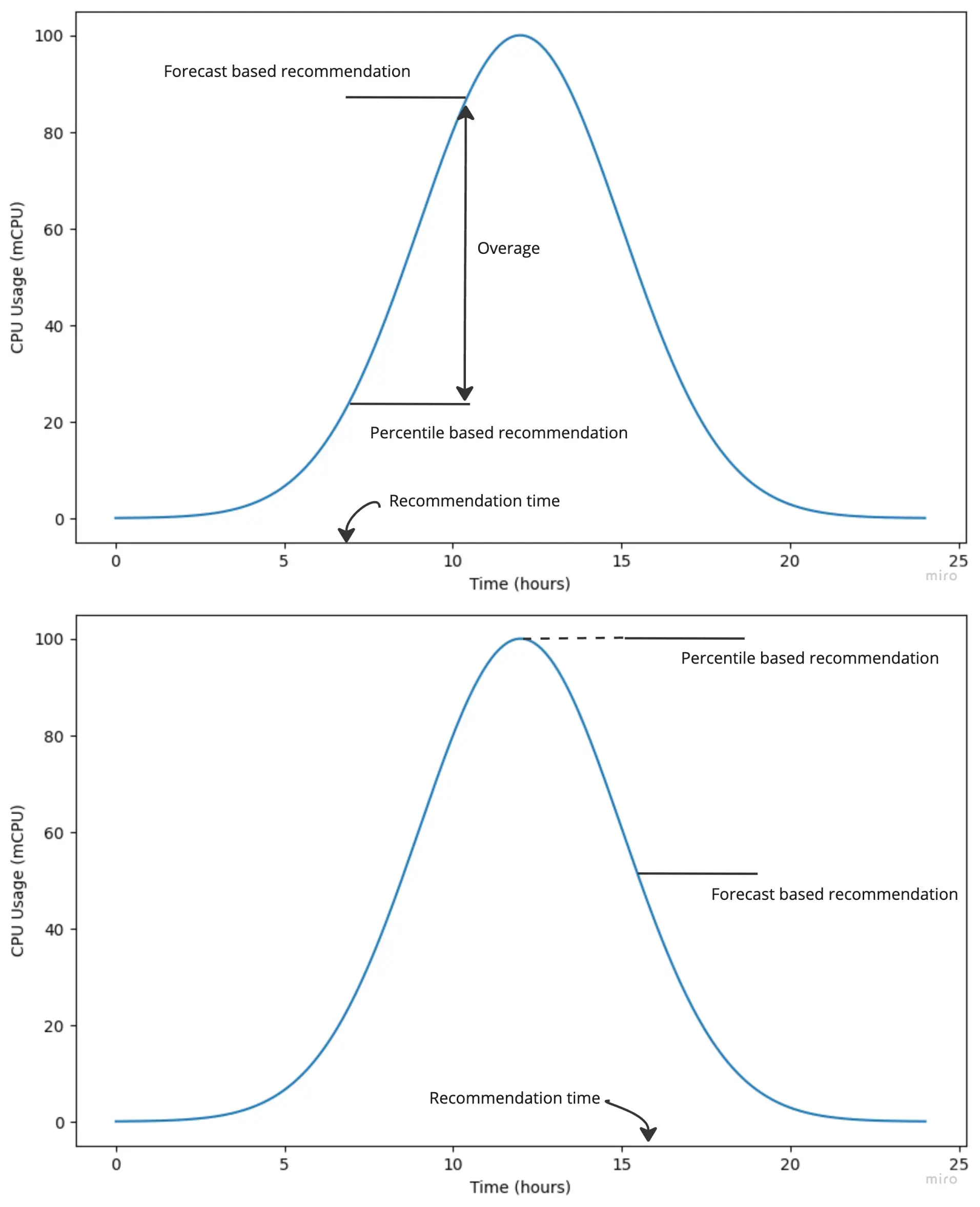
Figure 1 (below) illustrates the limitations of percentile-based approaches in handling increasing usage. At the time of recommendation, a percentile-based approach relies on historical values to determine the recommended resource requests. As usage continues to grow, this leads to overage, where the actual usage exceeds the requested amount. While overage may be tolerable for CPU, as it only results in throttling, it is particularly problematic for memory. When memory usage surpasses the requested value, it triggers an OOM error, causing significant disruption as Kubernetes is forced to restart the affected pod. In contrast, a forecast-based recommendation takes into account the predicted increase in usage and sets the request value accordingly, minimizing the risk of overage for the duration that the request value remains valid.
Similarly, when the usage decreases, a percentile-based approach uses the past peak in usage to make a recommendation, creating slack compared to a forecast-based recommendation. Summing the slack across the entire cluster accumulates to a tremendous amount of resources left unused, potentially leading to significant cost inefficiencies.
Not all workloads are the same. At StormForge, we work with over 100,000 workloads across various customers, providing us with extensive exposure to diverse workload usage patterns. Through this experience, we have identified two main workload types: noisy and seasonal. Our machine learning algorithm leverages this categorization to provide the most optimal recommendations for resource requests and limits.
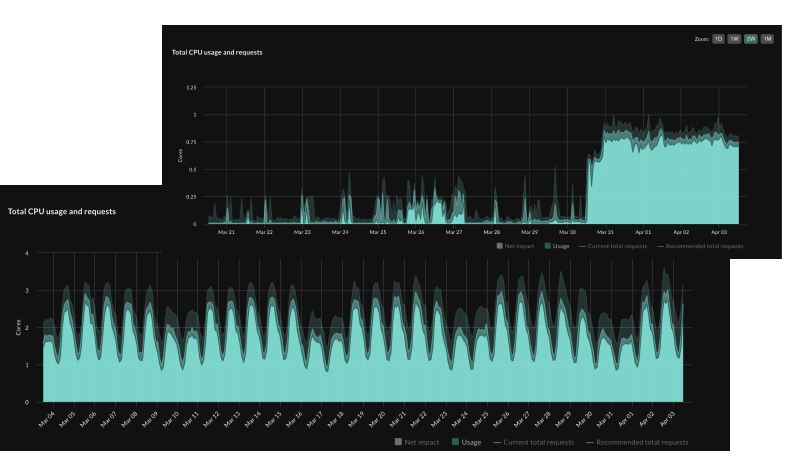
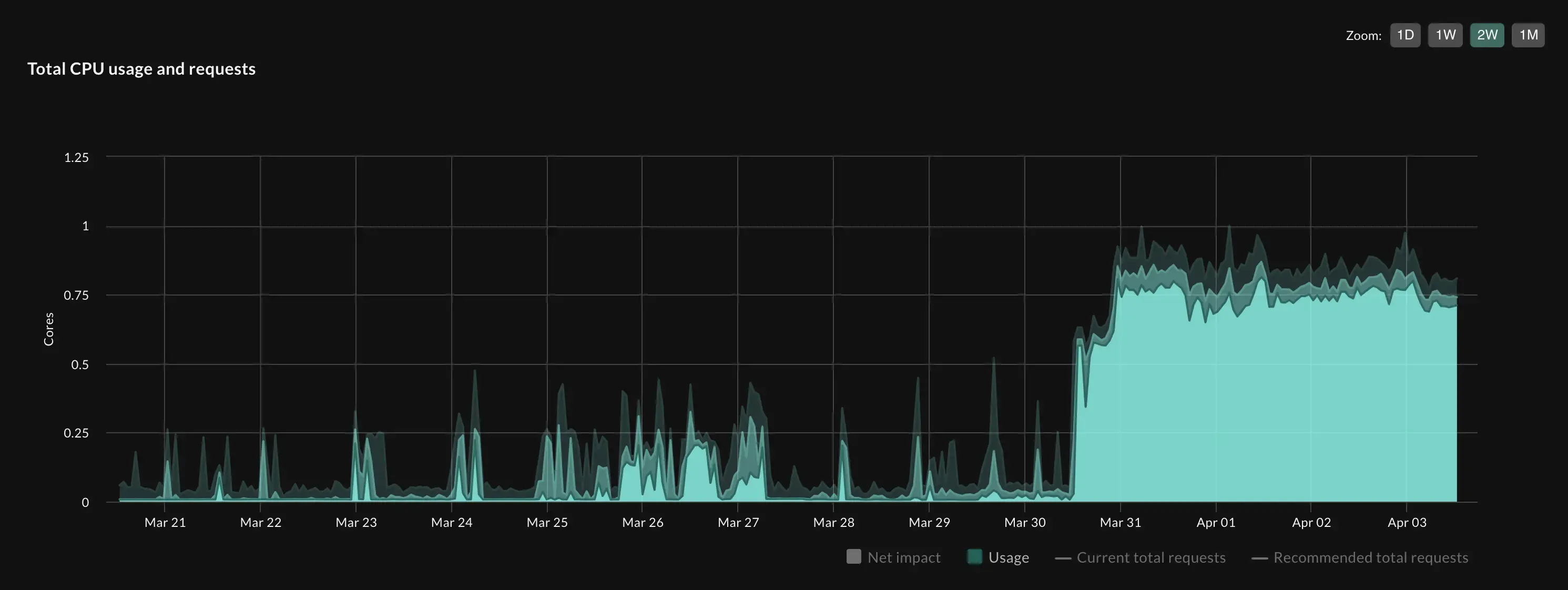
Noisy workloads are unpredictable, with no clear patterns to learn from. Figure 2 below shows a screenshot of the CPU usage of a noisy workload as displayed in Optimize Live.
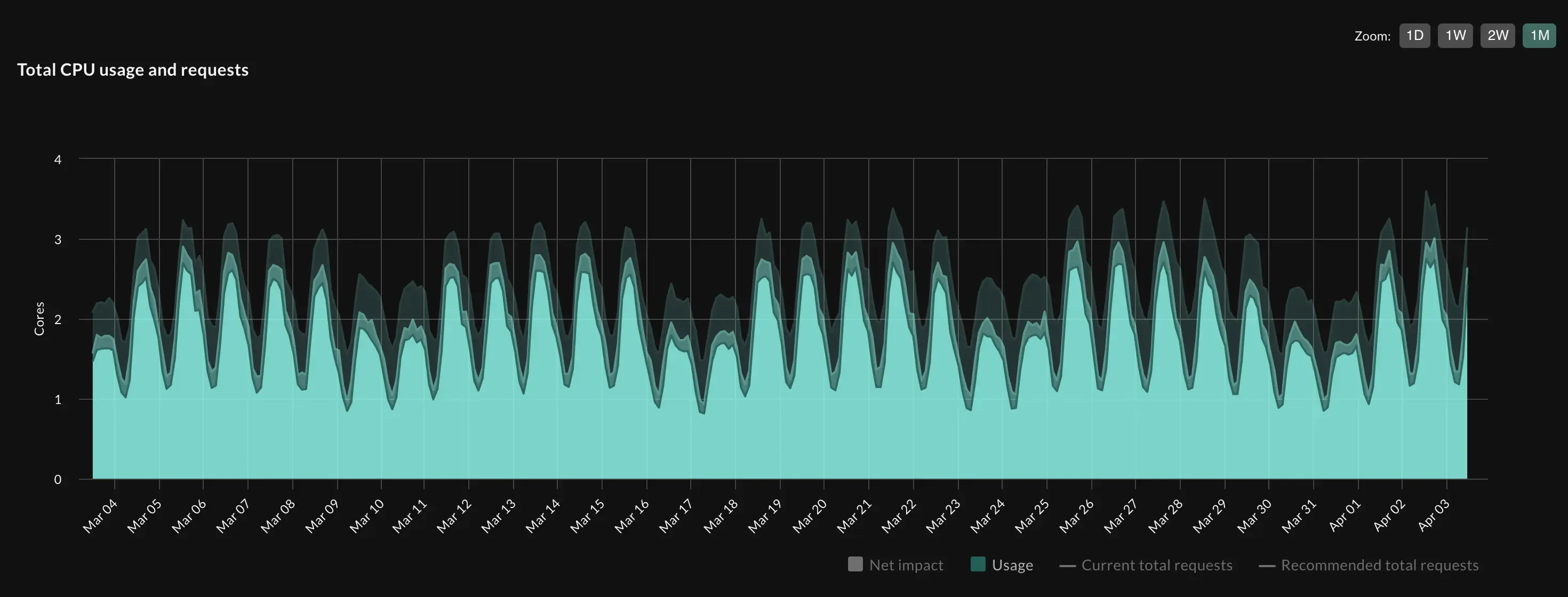
Seasonal workloads, on the other hand, exhibit trends and periodic patterns that our algorithm can learn from. Typical seasonal workloads show a significant increase in resource consumption during peak business hours (typically 9am-5pm, Monday to Friday), with notably decreased demands outside these periods. This is known as daily seasonality. Additionally, traffic often increases during weekdays and decreases over the weekend, representing a weekly seasonality.
Our machine learning algorithm goes beyond simply analyzing historical data by intelligently recognizing and adapting to trends, seasonal patterns, and noise levels in workload usage. This comprehensive approach allows Optimize Live to make accurate recommendations for both seasonal and noisy workloads.
Figure 4 (below) demonstrates how the machine learning algorithm understands daily and weekly seasonality, as well as the noise levels on top of these patterns. The gray data points represent the training data used to train the algorithm, while the purple data points indicate the test data that the algorithm needs to predict. The algorithm also captures trends, as evidenced by the slight increase in the base level of usage during the month of December.
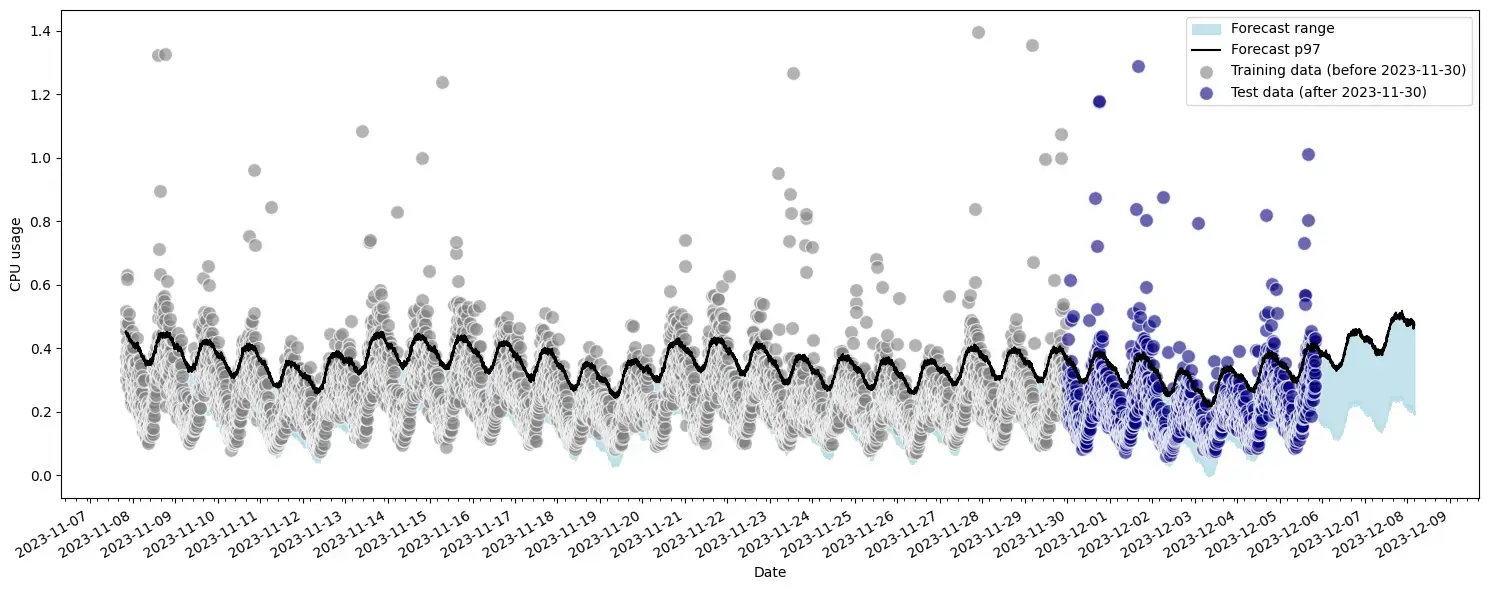
Recommendations for requests and limits are generated by forecasting usage and estimating the request values that minimize both slack and overage. This approach significantly improves upon the more generic percentile recommendation by optimizing for both the user’s cost and the application’s performance. By minimizing overage, our machine learning algorithm reduces the occurrence of CPU throttling, OOM errors, and pod disruptions, ensuring a more stable and reliable application.
Meanwhile, Optimize Live offers various settings (“savings,” “balanced,” and “reliability”) that allow users to specify whether the algorithm should prioritize minimizing slack (cost optimization) or overage (performance optimization). This flexibility is particularly useful when considering different resource types, such as CPU versus memory, or when dealing with applications of varying importance, like revenue-generating services versus less critical ones. By letting the user decide what the algorithm should prioritize, Optimize Live empowers them to make informed decisions based on their unique business requirements and objectives.
StormForge’s forecast-based algorithm, powered by machine learning, drastically improves workload rightsizing. By predicting usage patterns and proactively adjusting resource allocation, it ensures reliable application performance under fluctuating demands. This enhances user experience and enables effective scaling through automation.
Optimize Live empowers businesses to minimize both slack and overage, striking the perfect balance between cost optimization and application performance. By reducing resource waste and preventing issues like CPU throttling and OOM errors, businesses can significantly lower cloud costs while maintaining application resiliency.
Experience the benefits of forecast-based workload optimization firsthand with Optimize Live. Start a free trial or explore our sandbox environment to discover how StormForge can help you unlock the full potential of your Kubernetes applications while ensuring cost efficiency and reliability.
We use cookies to provide you with a better website experience and to analyze the site traffic. Please read our "privacy policy" for more information.


