Chapter 9 - Vertical Pod Autoscaler
Ensuring that your pod resource allocations are accurately rightsized is necessary for every Kubernetes administrator. Rightsizing pod resources like CPU and memory is required to optimize costs, reduce wasted worker node capacity, and maintain optimal performance.
Kubernetes administrators are well aware of the challenges of manually rightsizing pod resources with accurate values, especially in large-scale clusters. This article will educate you about the Vertical Pod Autoscaler (VPA), a Kubernetes component aimed at automating pod rightsizing to reduce operational overhead and improve cluster efficiency. By the end of this article, you will understand how the VPA works, its architecture, how to install it, and its limitations. You can use this knowledge to determine if the VPA adequately fulfills your requirements to automate pod rightsizing.
Summary of key Vertical Pod Autoscaler concepts #
What is the VPA? #
Administrators typically face multiple challenges when trying to optimize pod resource allocations manually. Statically defining CPU and memory values will result in resource allocations quickly becoming stale, creating overhead for administrators by requiring them to frequently commit and deploy updated resource allocations. Selecting accurate resource values and regularly revising them to keep up with workload requirements is a highly challenging task with performance and cost at stake. Additionally, manual updates and maintenance for static request values do not scale well in large clusters with hundreds or thousands of pods running, which means that admins will struggle to keep resource values precisely rightsized across whole clusters.
The VPA is a Kubernetes component that aims to automate pod CPU and memory allocation, ensuring that neither resource is overprovisioned or underprovisioned. The ability to precisely allocate pod resources provides several benefits:
- Application performance is sustained by preventing CPU throttling or out-of-memory (OOM) errors
- Worker node capacity requirements can be reduced, which results in smaller, simpler clusters, and optimized costs from mitigating wasted resources.
The VPA aims to improve cluster efficiency by using real-time metrics to rightsize pod requests and limits, reducing the operational overhead for administrators. In the rest of this article, we’ll look deeper into how the VPA tries to achieve this goal.
Architecture of the VPA #
The VPA’s functionality is driven by three core components: the Recommender, the Updater, and admission webhooks. They each work together to apply pod rightsizing recommendations. Administrators interested in implementing the VPA should understand how these components work in order to troubleshoot potential issues and optimize the VPA’s configuration.
Recommender
The Recommender is the most essential component of the VPA. Its responsibility is to calculate and model recommended pod resource values based on historical metrics. The Recommender relies on the Kubernetes Metrics Server component to provide insight into pod metric data for CPU and memory utilization. The Metrics Server is a Kubernetes component that scrapes each node’s Kubelet agent to gather node and pod utilization data. Note that it is not a replacement for a full-fledged monitoring tool. Its use case specifically serves autoscaling components like the VPA. The Recommender can optionally leverage Prometheus as a data store as well, but only for CPU and memory metrics.
The Recommender maintains a record of the cluster’s state in its memory. The state information will include the details of all pods running in the cluster, as well as their relevant metrics data. Each time the Recommender scrapes new data (every 1 minute), it will recalculate the resource allocation for pods in the cluster based on up to 8 days worth of metrics (stored in-memory). The Recommender will focus on setting pod request and limit values with the goal of reducing the likelihood of CPU throttling and OOM issues based on the peak utilization observed for each pod. It’s important to note that restarting a Recommender pod will cause it to lose the in-memory metrics, causing reduced recommendation accuracy until enough new metrics have been scraped to rebuild the data. Leveraging Prometheus instead of the metrics server ensures historical metrics are always available for the Recommender to utilize; however, this approach requires creating and maintaining a Prometheus installation.
Once the Recommender has computed new resource allocation values, it will update a custom resource called VerticalPodAutoscaler. The VPA project introduced this new resource type that configures various scaling settings based on the user’s requirements, such as the maximum allowed CPU and memory values and which pods to target. We’ll discuss installing the VPA’s resources more in another tutorial.
For now, let’s see how the Recommender displays new resource allocation recommendations within the VerticalPodAutoscaler resource:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: test-workload
status:
conditions:
- lastTransitionTime: "2024-03-05T06:53:56Z"
status: "True"
type: RecommendationProvided
recommendation:
containerRecommendations:
- containerName: test-workload
lowerBound:
cpu: 104m
memory: 262144k
target: # These values represent pod request recommendations.
cpu: 587m
memory: 262144k
upperBound:
cpu: "1"
memory: 500MiThe object above shows that the VPA has evaluated a test-workload deployment and generated new recommendations for request and limit values. The Recommender will generate these recommendations every few minutes based on recent metrics and update the status section of the VerticalPodAutoscaler object. The VerticalPodAutoscaler object also provides many configuration parameters for you to tweak, which we’ll see in the tutorial.
The Recommender also allows further customization of scaling settings via command-line flags passed into the Recommender’s container arguments. Administrators can use these flags to control scaling settings like how much safety margin to add for request recommendations and the minimum CPU/memory to allocate for a pod. A drawback to customizing these settings is that they’re applicable cluster-wide—they cannot be granularly configured per workload unless the administrator introduces complexity by running multiple Recommenders in parallel.
Autonomous Rightsizing for Kubernetes Workloads

Automated vertical autoscaling designed to scale for 100K+ containers

Fully compatible with HPA functionality and cloud-based services

Powered by advanced machine learning with user-controlled guardrails
Updater
Historically, updating a workload’s requests and limits requires pod replacement. This behavior may change in an upcoming Kubernetes version, with the “in-place” resource rightsizing feature currently in alpha. For now, when you want to update your pod’s resource allocation, you must replace the pods with an updated schema. This is where the Updater comes into play.
The Updater will monitor the VerticalPodAutoscaler object to see if the Recommender has changed its recommendations. The Recommender will change its recommendations if the pod’s utilization breaches the lowerBound or upperBound numbers. These thresholds are the Recommender’s estimate of the boundary within which the pod’s utilization will remain. If the pod’s utilization goes above/below the threshold, the Recommender will calculate an updated lowerBound, upperBound, and target value to reflect the pod’s current requirements. The Updater will monitor changes to the target value and is responsible for evicting the target pods to force a replacement. The new pod will contain the updated resource allocation values. The Updater will attempt to apply these changes gracefully by only evicting a small number of pods at once—never all pods in a deployment at the same time—and has a cooldown period to avoid unnecessary churn.
The Updater provides some customization options via container arguments, like the Recommender. Useful settings to customize include how frequently the Updater should execute evictions and how many pods can be evicted in parallel. Like the Recommender, the Updater does not support per-workload settings, making the customization options of limited use for clusters running multiple workloads with unique requirements.
Admission webhooks
The VPA leverages a useful Kubernetes feature called admission webhooks. Webhooks are a mechanism that validates and modifies Kubernetes objects before they’re persisted into the Kubernetes data store (called etcd). The API server will forward all incoming object creation/update events to any registered webhooks in the cluster, which can then validate or modify the object schema. The API server will then take the output and persist the data.
The VPA project includes a mutating admission webhook that will intercept all pods being deployed to the cluster. The VPA’s webhook injects the updated resource values into the incoming pods based on the data in the VerticalPodAutoscaler object. The API server will then record the updated pod’s schema, and the updated pod will be scheduled to run on a worker node.
Workflow summary
The overall workflow of theVPA is as follows:


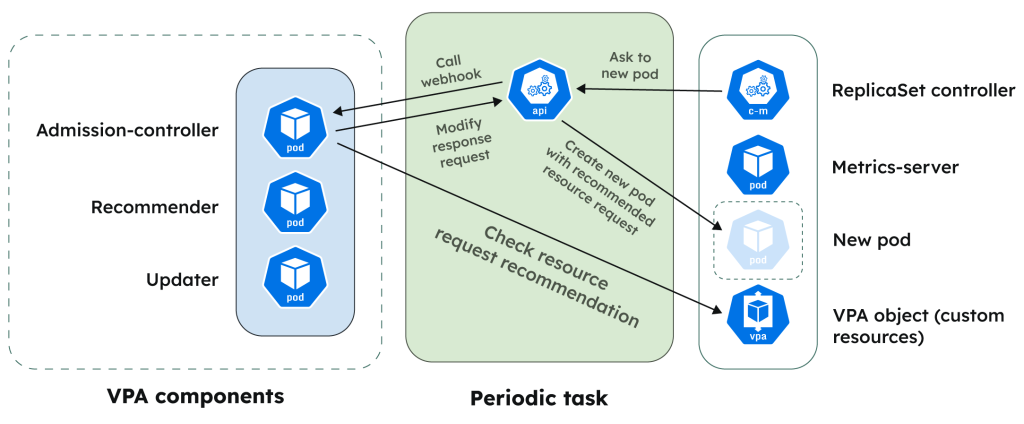
The workflow is now complete, and the pods have been rightsized. The Recommender will monitor pod resource utilization metrics continuously to update its recommendations.
Getting started with the VPA #
To see the VPA in action, let’s go through the installation process and verify that it is applying recommendations correctly.
Prerequisites:
Let’s start by installing the Metrics Server. It’s a simple component that the VPA will use to scrape pod metrics:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yamlThe VPA is one of the few Kubernetes projects that isn’t available as a Helm chart, so we’ll download it from GitHub and deploy the manifests directly.
# Clone the autoscaler project into your local directory:
git clone https://github.com/kubernetes/autoscaler.git
# Change directory into the VPA folder:
cd vertical-pod-autoscaler/The current directory contains the VPA’s manifests. The project provides a script to perform the VPA deployment:
./hack/vpa-up.shOnce the script above executes, we can see the VPA pods running with the three components we discussed earlier:
kubectl get pods -A | grep vpa
kube-system vpa-updater-884d4d7d9-56qsc Running
kube-system vpa-admission-controller-7467db745-xl5kp Running
kube-system vpa-recommender-597b7c765d-q5qz8 RunningNow we’re ready to create the VerticalPodAutoscaler object and some pods to test the VPA’s functionality. Let’s create a deployment with two pods. Notice that we’re defining some initial request and limit values for CPU and memory. The application below is expected to utilize more than the CPU resources allocated, so we expect to see the VPA recommend an updated allocation.
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-workload
spec:
replicas: 2 # a minimum of 2 replicas is required for VPA by default
selector:
matchLabels:
app: test-workload
template:
metadata:
labels:
app: test-workload
spec:
containers:
- args:
- -c
- while true; do timeout 0.5s yes >/dev/null; sleep 0.5s; done
command:
- /bin/sh
image: registry.k8s.io/ubuntu-slim:0.1
name: test-workload
resources:
limits:
cpu: 100m
memory: 50Mi
requests:
cpu: 100m
memory: 50MiNext, we’re ready to create the VerticalPodAutoscaler object. The object below configures the VPA with the following settings:
- Target a deployment called test-workload, which we created above. The Recommender will now analyze this deployment for rightsizing recommendations.
- Apply rightsizing recommendations based on data from all containers in the pod.
- Don’t recommend request and limit values higher than 1 CPU and 500Mi of memory.
- Don’t recommend request and limit values below 100m CPU and 50Mi of memory.
- Recreate pods to apply new recommendations. The alternative updateMode setting is Off, which is helpful for administrators who want to view recommendations without automatically applying the change.
Deploy the object below to begin rightsizing the test-workload pods:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: test-workload-vpa
spec:
resourcePolicy:
containerPolicies:
- containerName: '*'
controlledResources:
- cpu
- memory
controlledValues: RequestsAndLimits
maxAllowed:
cpu: 1
memory: 500Mi
minAllowed:
cpu: 100m
memory: 50Mi
targetRef:
apiVersion: apps/v1
kind: Deployment
name: test-workload
updatePolicy:
updateMode: RecreateOnce the object is deployed, the Recommender begins analyzing the CPU and memory utilization of the pods. Once a recommendation is ready, the VerticalPodAutoscaler object above will be updated with a new status field. It may take a few minutes for the Recommender to begin providing recommendations. Describe the object to view the recommendations:
kubectl describe verticalpodautoscaler test-workload-vpaThe output of the command above will show our original VerticalPodAutoscaler object, now with a new section:
Status:
Conditions:
Last Transition Time: 2024-03-05T10:33:56Z
Status: True
Type: RecommendationProvided
Recommendation:
Container Recommendations:
Container Name: test-workload
Lower Bound:
Cpu: 116m
Memory: 262144k
Target:
Cpu: 143m
Memory: 262144k
Uncapped Target:
Cpu: 143m
Memory: 262144k
Upper Bound:
Cpu: 1
Memory: 500MiThe status field shows that a recommendation was generated. The Target CPU is 143m, which means that the recommended request is higher than the original 100m. The memory recommendation is 262Mi, up from the original 50Mi value. The pod limit values correlate with the Uncapped Target value above, which, in this case, is the same as the request recommendation.
The expected behavior is that the Updater will see the recommendations above in the VerticalPodAutoscaler object and then evict the test-workload-vpa pods. We can see this in action by checking the Kubernetes events:
kubectl get events | grep test-workload
9m47s EvictedByVPA pod/test-workload-5bb4cd6fc-j9nrc Pod was evicted by VPA Updater to apply resource recommendation.
9m31s Created pod/test-workload-5bb4cd6fc-r84xf Created container test-workload
8m47s EvictedByVPA pod/test-workload-5bb4cd6fc-r89hb Pod was evicted by VPA Updater to apply resource recommendation.
8m30s Created pod/test-workload-5bb4cd6fc-dtt5s Created container test-workloadThe events above indicate that the VPA evicted both pods, which were rescheduled. An interesting thing to note is that the VPA waited one minute between evictions to reduce disruption instead of evicting both pods simultaneously.
Once the pods are evicted, the admission webhook should inject the values above into the replacement pods. Let’s check if the VPA updated our requests and limits:
kubectl describe pod test-workload-5bb4cd6fc-r84xf
Containers:
test-workload:
Limits:
cpu: 286m
memory: 262144k
Requests:
cpu: 143m
memory: 262144kWe can see that the request and limit values above correctly reflect the recommendations visible in the VerticalPodAutoscaler object. The values were raised from where we initially configured them, indicating that the VPA was able to update the resource allocation successfully.
VPA Limitations #
While the VPA can automate pod resource rightsizing, there are some drawbacks that administrators should be aware of. Carefully understanding the limitations of the VPA will help you determine whether this tool meets your requirements.
Limited access to historical metrics
The Metrics Server doesn’t store historical metrics. It only serves real-time data, so the VPA Recommender needs to store historical data to track historical patterns and make accurate recommendations. However, the VPA can only store up to eight days of data for analysis, which may not be sufficient for workloads where patterns only appear after more extended time periods. The VPA will also lose its data store if the VPA pods are terminated/restarted, causing the historical data to be lost.
The limited access to historical data and the fragility of the setup are significant drawbacks to using the VPA. Configuring a Prometheus server dedicated to enabling more detailed metrics can be a challenge due to the ongoing operational overhead required to maintain Prometheus.
Limited compatibility with the Horizontal Pod Autoscaler
The HPA provides useful functionality for scaling pod replicas, but it cannot be used in parallel with the VPA. Running both tools together for CPU- and memory-based scaling will result in unexpected scaling behavior and is warned against by the maintainers of both projects. “Resource thrashing” will occur when the tools are run together, meaning that each tool will continuously trigger conflicting scaling actions and the workload will not stabilize on an optimized resource configuration. According to a Datadog report, the HPA is used by almost 55% of organizations, meaning that a large number of Kubernetes administrators will be blocked from using the incompatible VPA tool.
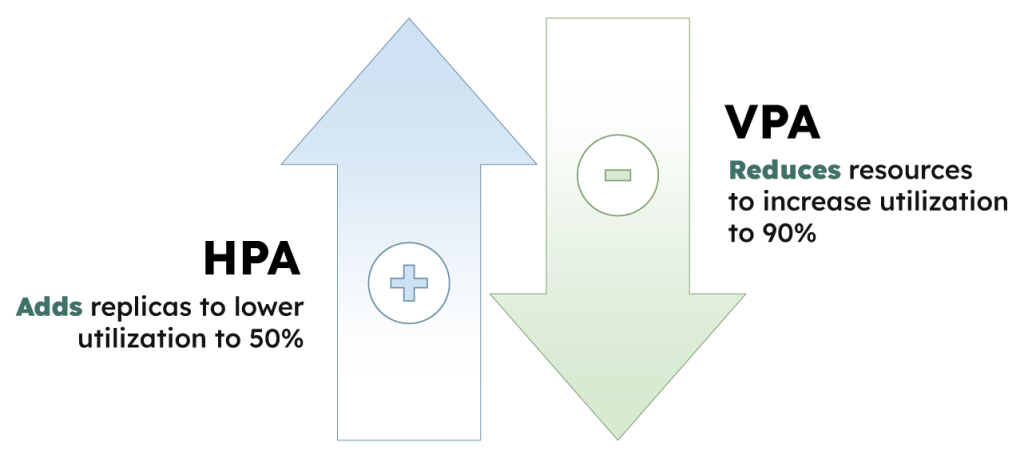
Service interruptions occur when updating single replica workloads
By default, the min-replicas value on the updater is set to 2, meaning that the updater won’t evict pods for workloads that have fewer than two replicas. This is because for workloads that run only one pod at a time, pod eviction caused by the VPA’s updater will necessarily result in a momentary interruption of service. The VPA’s Recreate update mode for rolling out new recommended values will delete pods before their replacements are created.
If service interruptions like this are acceptable, administrators can change the VPA updater’s min-replicas value to 1 using a command-line flag. This setting applies cluster-wide, and cannot be customized for individual workloads without running and configuring multiple updaters.
Inability to use time windows
The VPA’s rollout of recommendations cannot be controlled by time windows. Pod evictions will take place at any time when resource rightsizing is required, which is not suitable for production environments where deployments are typically frozen during certain time periods (like outside business hours or during peak traffic periods). VPA users must be prepared for their pods to be evicted at any time, including if a usage spike triggers the Updater to evict pods to revise resource allocation. This situation can be a challenge since the Updater will be evicting pods which are doing the most work under load, and relies on the user to configure PodDisruptionBudgets and deploy enough replicas to handle partial interruption.
Potentially confusing customization
The configuration of the VPA’s components is done via a mixture of the VerticalPodAutoscaler object and the VPA container’s command-line flags. This approach to customization may be confusing for administrators since settings can be configured in multiple places.
Additionally, command-line settings are applied to all workloads cluster-wide, which won’t be suitable for workloads that have unique requirements. Running multiple VPAs is required to tailor scaling settings per workload, which isn’t scalable for clusters with hundreds or thousands of workloads.
Managing a large number of VerticalPodAutoscaler resources with unique settings will also increase operational overhead for administrators, especially if settings need to be updated over time.
Lack of a graphical interface
The VPA doesn’t provide an interface to easily view the rightsizing status of all pods in a cluster. Administrators can only gain insight into the status of recommendations by querying the VerticalPodAutoscaler object manually, which isn’t scalable in large clusters with many workloads deployed. Ideally, administrators would have access to an interface where all pod rightsizing recommendations are centrally visible.
StormForge: a better option #
The VPA’s goal of improving cluster efficiency by automating resource settings is valuable and sought after, but its significant limitations mean that few organizations, if any, have successfully capitalized on those objectives. The Datadog report showing that almost 55% of organizations are using HPA also revealed that less than 1% are using VPA, a rate that has remained flat since 2021.
The limitations of the VPA do not mean that the target objectives are impossible. StormForge Optimize Live is an alternative vertical pod autoscaling tool that offers all of the VPA’s features and expands on them while addressing the limitations above.
StormForge is a pod rightsizing tool with an advanced approach that leverages machine learning to analyze both historical and real-time data. It provides a per-workload level of customization for all behavior, as well as hierarchical configuration to let users customize autoscaling behaviors that apply either across the entire cluster or each individual namespace sequentially. StormForge’s graphical user interface allows administrators to visualize the recommendations it provides across multiple clusters, offering a central location to view and apply recommendations. StormForge is also compatible with the HPA and provides functionality to export recommendations as YAML patches to automatically integrate into your source control.
Conclusion #
The Kubernetes VPA is an intriguing tool for cluster administrators to automatically rightsize pod CPU and memory resources. Pod rightsizing improves cluster efficiency, reduces wasted compute resources, and improves cost efficiency.
The VPA leverages three components to perform its rightsizing tasks: the Recommender, Updater, and admission webhooks. These components work together to generate recommendations based on pod utilization metrics and then apply the updated values to any targeted pod in the cluster.
Experimenting with the VPA in your own Kubernetes cluster is a valuable way to familiarize yourself with the project and the resources it uses to apply rightsizing. Administrators are encouraged to modify the VerticalPodAutoscaler object to experiment with various configurations to help learn how it works and whether it is able to fulfill their requirements.
Administrators should be aware of some key limitations of the VPA before rolling out the project to a production environment. Limitations related to incompatibility with the HPA, the lack of a friendly graphical interface to view and apply recommendations, and the basic recommendation modeling being based on peak utilization may limit the VPA’s effectiveness for many environments.
An alternative vertical pod autoscaling tool like StormForge provides more advanced functionality, such as cluster, namespace, or workload-scoped configuration, and recommendations generated by machine learning. Administrators should carefully evaluate options to determine what suits their requirements.
You can test out StormForge for free or play around in the sandbox environment.